이진 탐색 알고리즘은 순차 탐색 알고리즘보다 훨씬 좋은 성능을 보이는 알고리즘이다.
하지만 배열을 대상으로 이진 탐색 알고리즘을 적용하기 위해서는 다음의 조건을 만족해야만 한다.
"배열에 저장된 데이터는 정렬되어 있어야 한다."
즉, 이진 탐색 알고리즘은 정렬된 데이터가 아니면 적용이 불가능하다 (정렬의 기준 및 방식과는 관계없다).
만약 길이가 9인 배열이 있다고 가정하면...
arr[0] | arr[1] |
arr[2] |
arr[3] |
arr[4] |
arr[5] |
arr[6] |
arr[7] |
arr[8] |
1 |
2 |
3 |
5 |
9 |
12 |
25 |
31 |
45 |
이진 탐색 알고리즘의 첫 번째 시도:
1. 배열 인덱스의 시작과 끝은 각각 0과 8이다.
2. 0과 8을 합하여 그 결과를 2로 나눈다.
3. 2로 나눠서 얻은 결과 4를 인덱스 값으로 하여 arr[4]에 저장된 값이 3인지 확인한다.
즉, 배열의 중앙에, 찾는 값이 저장되어 있는지 확인하는 것이 이진 탐색 알고리즘이다.
이진 탐색 알고리즘의 두 번째 시도:
1. arr[4]에 저장된 값 9와 탐색 대상인 3의 대소를 비교한다.
2. 대소의 비교결과는 arr[4] > 3 이므로 탐색의 범위를 인덱스 기준 0~3으로 제한한다.
3. 0과 3을 더하여 그 결과를 2로 나눈다. 이때 나머지는 버린다.
4. 2로 나눠서 얻은 결과가 1이니 arr[1]에 저장된 값이 3인지 확인한다.
두 번째 시도 과정에서 주의 깊게 살펴볼 것은 탐색의 대상을 반으로 줄였다는 사실이다. 이는 어디까지나 배열에 데이터가 정렬된 상태로 저장되었기 때문에 가능한 일이다.이것이 바로 이진 탐색 알고리즘의 핵심이다.
이진 탐색 알고리즘의 세 번째 시도:
1. arr[1]에 저장된 값 2와 탐색 대상인 3의 대소를 비교한다.
2. 대소의 비교결과는 arr[1] < 3 이므로 탐색의 범위를 인덱스 기준 2~3으로 제한한다.
3. 2와 3을 더하여 그 결과를 2로 나눈다. 이때 나머지는 버린다.
4. 2로 나눠서 얻은 결과가 2이니 arr[2]에 저장된 값이 3인지 확인한다.
이렇듯 두 번째 시도 이후부터는 탐색 대상을 찾을 때까지 동일한 패턴을 반복할 뿐이다. 하지만 세 번째 시도를 진행하면서 탐색 대상인 3을 찾게 되니, 이로써 탐색은 마무리가 된다.
이진 탐색 알고리즘은 탐색의 대상을 반복해서 반씩 떨구어 내는 알고리즘이다. 때문에 순차 탐색 알고리즘에 비해 좋은 성능을 보인다.


위의 이진 탐색 알고리즘에서 last = mid-1; 과 first = mid+1; 에 감소와 증가가 없다면 어떻게 될까?
값을 하나 빼거나 더해서 그 결과를 변수 last와 first에 저장하지 않으면, mid에 저장된 인덱스 값의 배열요소도 새로운 탐색의 범위에 포함이 된다. 그런데 이는 불필요한 일이다. mid의 배열요소에 탐색 대상이 저장되어 있는지 검사가 이미 끝난 상태이기 때문이다.
그런데 더 큰 문제가 존재한다. 무엇이냐면...
문제는 탐색의 대상이 배열에 존재하지 않는 경우... 무한루프를 형성하며 프로그램이 종료되지 않는다는 것이다.
탐색의 대상이 배열에 존재하지 않을 경우 first에 저장된 값이 last보다 커져서 반복문을 탈출할 수 있어야 하는데, 위와 같이 코드를 수정하고 나면 결코 first에 저장된 값은 last 보다 커질수 없다 (last는 first보다 작아질 수 없다).
때문에 무한루프를 형성하게 되는 것이다.
감소나 증가를 하지 않는다면...기본적으로 세 변수에 저장된 인덱스 값은 항상 다음의 식을 만족하도록 알고리즘이 디자인된다.

감소나 증가를 뺀다면, mid에 저장된 값을 가감 없이 first 또는 last에 저장하는 것이 전부이다. 그래서 first는 결코 last보다 커질 수 없고, last는 결코 first보다 작아질 수 없다.
이진 탐색 알고리즘의 시간 복잡도 계산하기 : 최악의 경우(Worst Case)를 기준
우선, 연산횟수를 대표하는 연산이 무엇인지 찾아야 한다.
그런데 이 역시 탐색 알고리즘이니 순차 탐색 알고리즘과 마찬가지로 == 연산을 연산횟수를 대표하는 연산으로 볼 수 있다.
"데이터의 수가 n개일 때, 최악의 경우에 발생하는 비교연산의 횟수는 어떻게 되는가?"
- 데이터의 수 n이 n/2, n/4, n/8... 이렇게 줄어서 1이 될 때까지 비교연산을 한 번씩 진행하고, 마지막으로 n이 1일 때 비교연산을 한 번 더 진행한다. 그리고 그것이 탐색 대상이 존재하지 않는 최악의 경우의 비교연산 횟수이다. 그러니까 데이터의 수가 8개였다면 8,4,2,1 이렇게 줄어드니 총 4회 비교연산이 진행된다.
위와 같이 답을 내릴 수 있다. 하지만! 이 정도의 정보는 성능의 분석 및 비교에 사용할 수 없다.
이 정도의 정보를 가지고 앞서 다른 탐색 알고리즘과의 객관적 성능 비교는 가능하지 않다.
위의 데이터의 수가 8개인 상황에서의 비교연산 횟수는 다음과 같이 정리할 수 있다.
# 8이 1이 되기까지 2로 나눈 홧수 3회, 따라서 비교연산 3회 진행.
# 데이터가 1개 남았을 경우, 이때 마지막으로 비교연산 1회 진행.
↓↓↓↓↓ 다시 정리하면...
# n이 1이 되기까지 2로 나눈 횟수 k회, 따라서 비교연산 k회 진행.
# 데이터가 1개 남았을 경우, 이때 마지막으로 비교연산 1회 진행.
이로써 비교연산의 횟수를 구했으니, 최악의 경우에 대한 시간 복잡도 함수 T(n)은 다음과 같이 정리된다.
# 최악의 경우에 대한 시간 복잡도 함수 : T(n) = k + 1
2로 나눈 횟수 k 구하기.
n이 1이 되기까지 2로 나눈 횟수가 k이니, n과 k에 관한 식을 다음과 같이 세울 수 있다.
 => n에 8을, k에 3을 대입하면 식은 성립된다. ex) 8 * pow((1/2.0), 3) 하면 1이 나올 것이다. 이 식은 2로 몇 번을 나누어야 1이 되는가에 대한 답을 주는 수식이다.
=> n에 8을, k에 3을 대입하면 식은 성립된다. ex) 8 * pow((1/2.0), 3) 하면 1이 나올 것이다. 이 식은 2로 몇 번을 나누어야 1이 되는가에 대한 답을 주는 수식이다.
▶  ▶
▶ 
※  과 같기 때문에.. 이런식이 나올 수 있다.
과 같기 때문에.. 이런식이 나올 수 있다.
이제 정리된 최종 수식의 양 변에 밑이 2인 로그를 취한다.
▶  ▶
▶  ▶
▶ 
이렇듯 k는 log2n 이다. 따라서 이진 탐색 알고리즘의 최악의 경우에 대한 시간 복잡도 함수 T(n) 은 다음과 같다.

그런데.. 위에 +1이 있었다. 하지만 +1은 중요하지 않다.
중요한 것은 데이터의 수 n이 증가함에 따라서 비교연산의 횟수가 로그적(logarithmic)으로 증가한다는 사실이다.
"식을 구성하면 데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단할 수 있다."
즉, n에 대한 식 T(n)을 구성하는 목적은 데이터 수의 증가에 따른 연산횟수의 변화 정도를 판단하는 것이므로 +1은 중요하지 않다.










































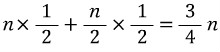
 함수그래프그리기.exe
함수그래프그리기.exe